
去年9月份和风雨狂行简单在线与大家进行了交流,原本计划去年就整理出来一些文档发布,供大家参考,无奈一直拖……。
闲话了,“鸿爪踏雪泥,还是来得及”。
现在接着把这件事情做了。
一、基础
这一部分大家参考公众号Py基础模块,这里不再说明。
二、地理数据处理——时间序列数据处理
在视频中关于这一部分讲的十分详细,这里只说明用处理这一部分,供大家参考。
和课程一样,还是从例子入手。首先是数据(txt文件),如下图,最终目标是求取数据的月平均。
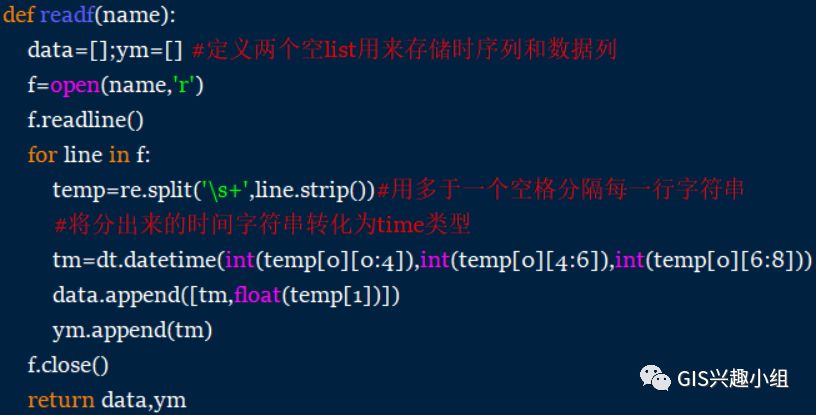
(1)利用基础对数据预处理
读入数据,存入的最主要的数据结构(如果只有索引和一列数据,可以定义为,为了方便,大家可直接定义为)。关于第一步处理的脚本在py基础中也有,这里只贴出代码,如下图:
如果是原始数据是csv格式,那我们直接用调用中的即可读入数据,不需要上边这么麻烦。具体如下:
df=.(,=0,=0,=True)。其中,就是定义索引列,是定义表头,而是将指定列转换为时间标识,值为True是将索引列转为时间。
(2)求时间序列均值
如果是txt,这里需要接收readf的返回值并构造,构造的格式很多,这里说一个比较常用的——将你要处理的数据处理为数组或者规则的list(例子中是规则的n*m的list),然后赋予其和索引即可,如下:
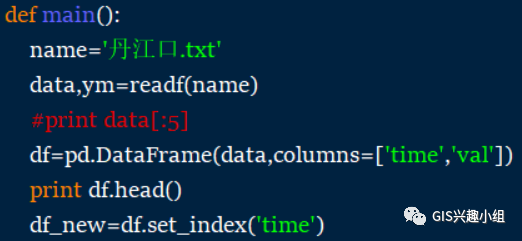
完成的构建,剩下的处理在中都是写好的现成的函数,十分简单。在此例中,要求月平均,实际上是对天数据的一个重采样,的函数能完美的处理这一操作,一句话即可完成笨办法数十行代码的处理方式(参见视频)。
df.(‘M’).mean()
这里仔细介绍这个用处极大的方法,首先方法目标是将按指定的方法分成很多个group,这个方法很多,这里指定的是’M’,即月(MS是将月的第一天作为最终索引),此外还有很多:’W’周 ‘Q’季度 ‘AS’年 ‘SM’半月 ‘S’秒 ‘H’小时 ‘T’分钟,甚至可以指定’5T’、’10H’等等,至于后边的处理就更容易理解了,当你把数据完成分组后,你想干啥都成,mean、sum、等等。例子中的结果如下:
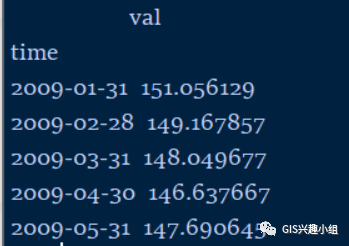
如果进一步扩展,要index只显示月,不到日,因为均值之后日没有意义,此时可以直接(),具体如下:
df.(‘M’).mean().(‘M’)
函数中的参数与中一致即可,十分简单。
(3)保存
保存很简单,建议大家以后全部保存成csv,方便查看,进阶的同学有些数据也可以直接存为nc,这个咱们后边再说。具体语法df.(),就是这么简单。有没有发现,如果你将txt另存为csv文件后,实际上你只需要三句核心代码即可求均值。
核心代码:
df=(‘aa.csv’,=0,=0,=True)
df.(‘M’).mean().()
df.(‘bb.csv’)
希望大家处理自己数据的时候举一反三,有问题欢迎在QQ群:交流
加入IP合伙人(站长加盟) | 全面包装你的品牌,搭建一个全自动交付的网赚资源独立站 | 晴天实测8个月运营已稳定月入3W+
限时特惠:本站每日持续更新海量内部创业教程,一年会员只需98元,全站资源免费无限制下载点击查看会员权益
站长微信: qtw123cn



